8 minutes read | published @ July 15, 2019
From synchronous service calls to message-passing dataflow systems
In this past year I have been working on a big system that is fundamentally an ETL to process real estate data across the US and Canada. I can’t talk much about the business details, but let’s say that if you’re browsing for real estate properties, it’s very likely you’re using this system. You’re welcome. Or I’m sorry, who knows?
I joined this project from the very beginning. When I joined, a couple of technical decisions had been made. Initially, before I’d arrived on this project, the microservices would talk to each other directly, REST/gRPC style. Nothing new here.
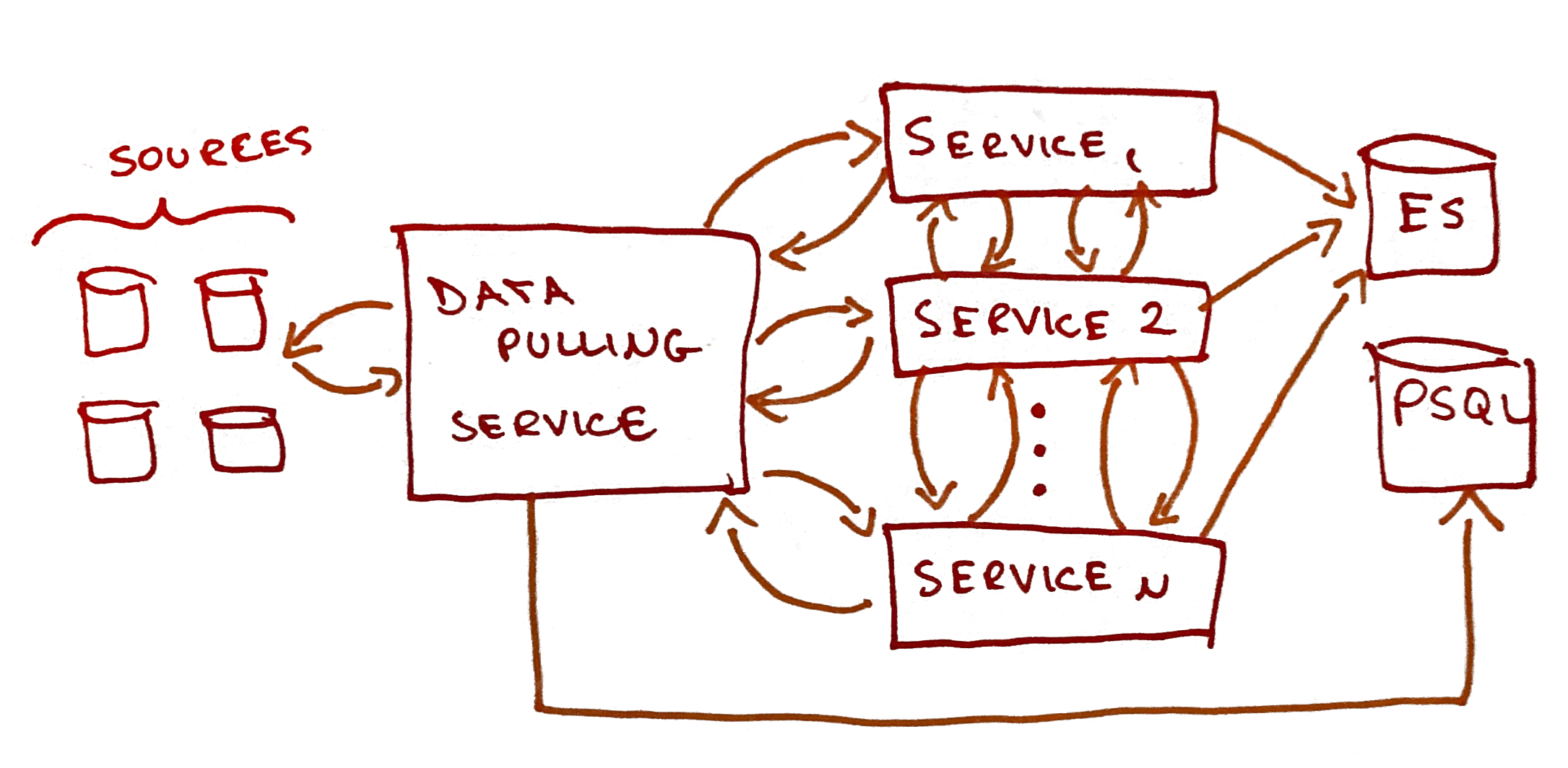 Simple architecture where the services talk to each other directly
Simple architecture where the services talk to each other directly
The great majority of these services communicated with each other through synchronous calls. In most scenarios, this would be 100% fine. In an ETL constantly streaming copious amounts of data that need fast processing though? Not so much.
One big problem with this architecture is that this application isn’t an “user-triggered” application and the events happens in a streaming fashion, i.e this is a streaming system, synchronous calls then quickly become a bottleneck. For instance: to process property X we’d need to wait for all other services to do their jobs before moving onto the property X + 1.
And because of that property (streaming system), it means we can go full asynchronous here; we want to stream data in a constant flow and each service will do its job independently.
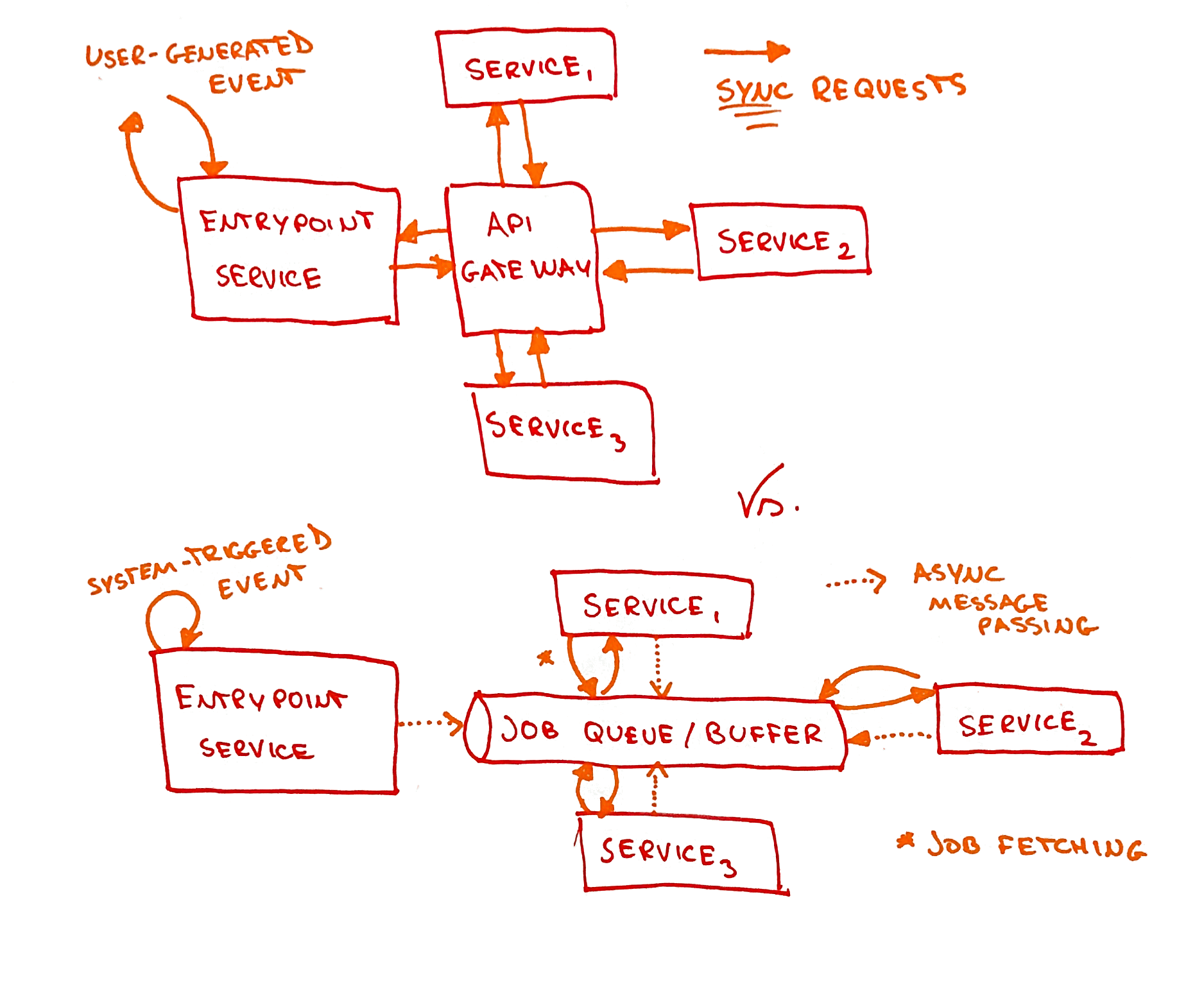 Direct communication through an API gateway vs. streaming system using message-passing (fully async)
Direct communication through an API gateway vs. streaming system using message-passing (fully async)
However, an unfortunate bad technical decision had been made before I arrived on this project: yes, they would go from sync requests to async requests, but they would do it through a service developed internally called Queuer, which, in hindsight, was nothing like a queue. Queuer would just take the request coming from one service, buffer it, and route it to another service (again, not a queue), which sounded more like what you’d get from a service mesh, but without all the reliability that you’d get from battle-tested robust tools. We had something like this:
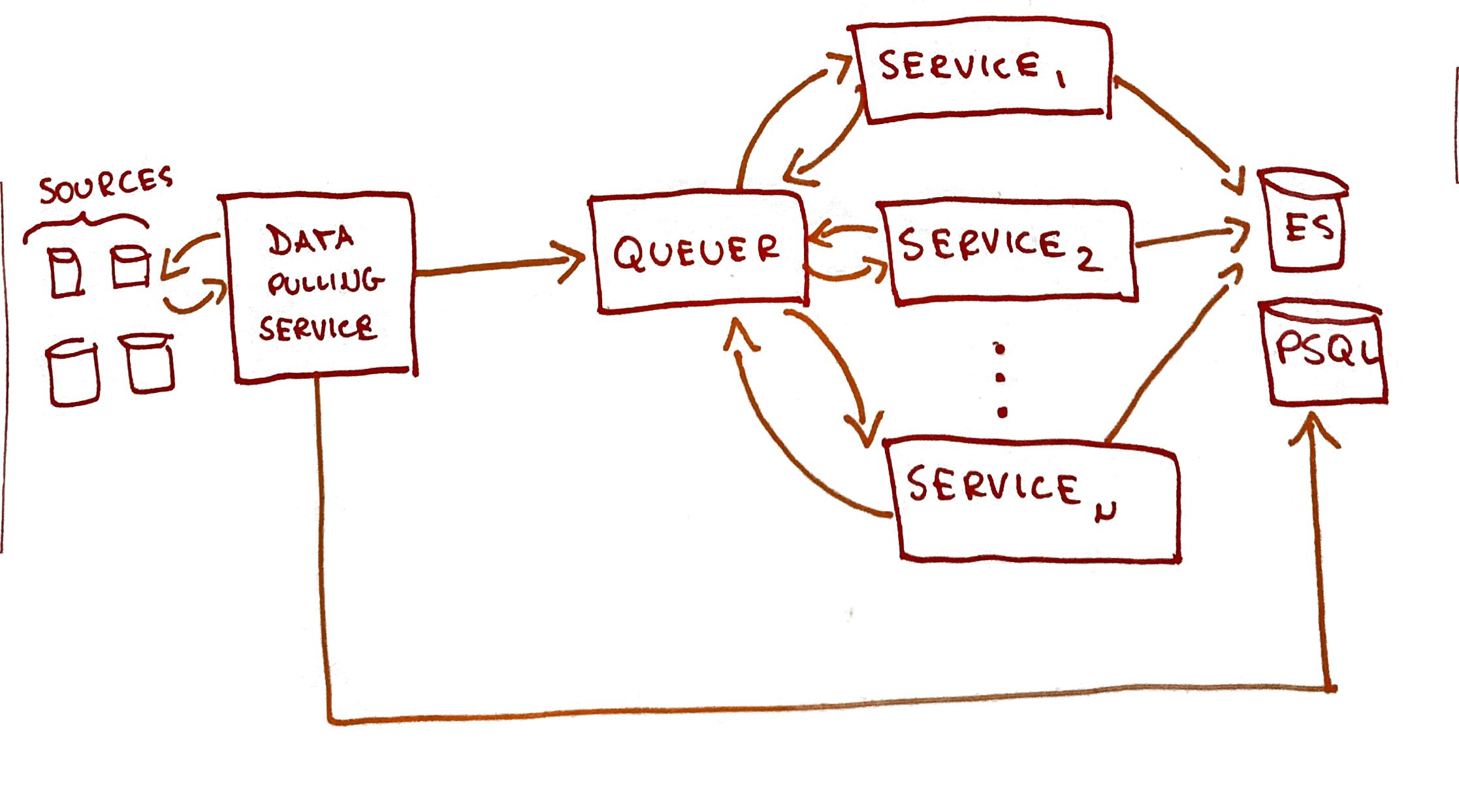 A queueing system that acts exactly like an API gateway
A queueing system that acts exactly like an API gateway
We had many problems with this:
- Maintaining a “queueing” system built in-house was terrible.
Queuerwasn’t service-agnostic; we had to encode domain knowledge about other services insideQueuer.- My favourite: Queuer had a buffer, which was simply a in-memory variable. It would buffer thousands of jobs there. If queuer died, well, the jobs were lost. Oh and forget about deliver-once guarantees and/or other goodies you can get by using a battle-tested queueing system such as RabbitMQ or Kafka.
About 3 months into the project I convinced people to move away from Queuer, it had become too much of a hassle to maintain and evolve it. Godspeed Queuer.
Also, around that time I was reading designing data-intensive data applications. It advocates – with very good arguments – for what’s called Message-Passing Dataflow. I’d seen this somewhere else with the name event-centric architecture or something like that; but I believe the philosophies between them are very similar. I like the simple way the author explains it, so here it is:
Composing stream operators into dataflow systems has a lot of similar characteristics to the microservices approach. However, the underlying communication mechanism is very different: one-directional, asynchronous message streams rather than synchronous request/response interactions.
I then decided to experiment with Message-Passing Dataflow; after all, we’re talking about a never-ending stream processing system. Therefore, I didn’t want much synchronous communication between the services and wanted something that’s closer to an actual streaming system.
To achieve this, we need a central component that would act as a communication bus, streaming messages between the services. And the services, instead of being just HTTP rest APIs, would be active consumers, consuming messages from this bus.
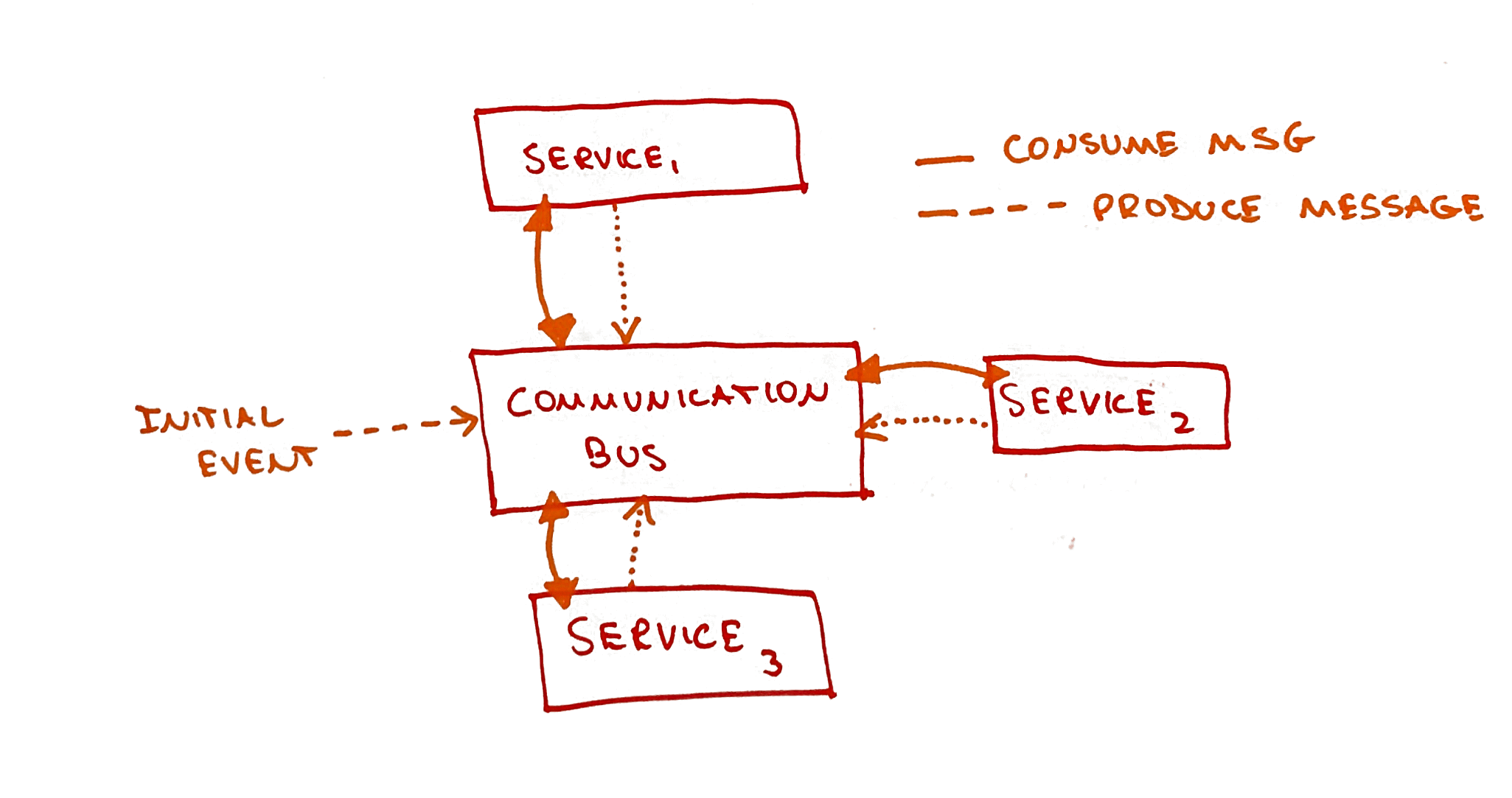 Services consume messages being passed to the channels they’re subscribed to
Services consume messages being passed to the channels they’re subscribed to
Not surprisingly, I decided to use Kafka as our communication bus. The services around Kafka are Kafka consumers and producers. All communication between the services happens through message passing.
Here are some observations after adopting this paradigm:
Async usually means that it will be faster
I noticed that this approach is faster that what we had before. A service does one thing and does it as fast as it can and don’t have to wait for the next steps. Then, it might produce a message to Kafka, which will be a job being performed by other services, and that’s it.
More robustness
This approach is much, much more robust. All services are completely stateless and they don’t hold jobs in memory. The service died? All good, the job can be easily recovered from Kafka, Kafka only moves its offsets when the offsets are commited, i.e when the service actually finishes the job.
You must think about how you handle the offsets
Even though it’s robust, consumers must be smart about it. Consuming offsets from topics (think of it as jobs in a queue) and failing to commit the new offset properly can be catastrophic. For instance, if we have a Kafka producer’s auto.commit enabled, the service reads a message from a topic, the auto commit mechanism commits after a few milliseconds, but then the process fail. That means we marked that offset as consumed, but we didn’t finished the job, so it’s… well, lost. Manually committing the offsets is much more reliable in high risk cases.
A different and refreshing computational model
It’s a very different computational model. Instead of proactively querying things from other services, we subscribe to channels of messages (called topics) and work our way through the messages in there. It’s closer to Alan Kay’s view of object-oriented programming (https://ovid.github.io/articles/alan-kay-and-oo-programming.html). And I’m not talking about that OOP created by the C++/Java community, but the core ideas of OOP thought by Kay and colleagues back in the early days of computing – which curiously was grounded in Biology. The idea of passing messages to objects in order to better scale systems (like biological cells do!). Kafka is nothing but a (very reliable) communication bus, and the objects (services, microservices, whatever) attach themselves to it and listen to messages, responding accordingly and sending other kinds of messages back to kafka which will be consumed by other services. Once you have well-defined messages and protocols, things flow beautifully.
Watch out for waste
Be careful with idle consumers, that means you gotta think about your partitions carefully. What’s worked for us is to set 1:1 partition-to-consumer ratio. For instance, we have an image processing service that fetches jobs from kafka. If we have more instances of that services than partitions, that means some of those instances will be idle, preventing us from achieving a higher throughput than we could.
Closing thoughts
I am, now, a big fan of this architectural style I can totally recommend if it fits your problems. Which in most cases it does. I believe we’ve been going with the flow that was set in the early 00s when it comes to architecting systems; we’ve been using the request-response paradigm without really questioning its efficacy.
To close, the author of designing data-intensive applications has some really cool insights about this paradigm:
It would be very natural to extend this programming model to also allow a server to push state-change events into this client-side event pipeline. Thus, state changes could flow through an end-to-end write path: from the interaction on one device that triggers a state change, via event logs and through several derived data systems and stream processors, all the way to the user interface of a person observing the state on another device. These state changes could be propagated with fairly low delay—say, under one second end to end.
Some applications, such as instant messaging and online games, already have such a “real-time” architecture (in the sense of interactions with low delay, not in the sense of “Response time guarantees”). But why don’t we build all applications this way?
The challenge is that the assumption of stateless clients and request/response interac‐ tions is very deeply ingrained in our databases, libraries, frameworks, and protocols. Many datastores support read and write operations where a request returns one response, but much fewer provide an ability to subscribe to changes—i.e., a request that returns a stream of responses over time.
In order to extend the write path all the way to the end user, we would need to funda‐ mentally rethink the way we build many of these systems: moving away from request/ response interaction and toward publish/subscribe dataflow. I think that the advantages of more responsive user interfaces and better offline support would make it worth the effort. If you are designing data systems, I hope that you will keep in mind the option of subscribing to changes, not just querying the current state.
My next steps? Experimenting with this architecture for applications where the events are user-triggered and the results are near real-time and user-facing.